

Sifting value from hype in recent tech
Sifting value from hype in recent tech
Detailed notes on the approach I have taken

Having seen the impact of the DotCom and 2008 financial collapses, I’ve been keen to learn to sift value from the hype on the recent tech innovations.
My approach
Building a mental model of the workings, capabilities and limitations of the tech building blocks.
Learn from thinkers who provide persuasive arguments about the limitations, hype and risks, and relate to learnings from the past like “big data”
Maintain a simple set of heuristics to evaluate ideas/initiatives when you don’t have sufficient information of the specifics
Building a mental model
I find it useful to build a broad, approximate model of the concepts before diving into the details iteratively. In my previous post I linked some resources that helped me discover resources to develop this mental model. Here are a few more resources along with the concepts that each video helped me approximate.
This video helped refresh my understanding of neural networks using character recognition as the concrete use case. A picture presents a thousand words and here’s a simple screen grab from the video that allows one to think about tokenisation - how do you convert a subjective/human concept into digital information that a computer system can process.
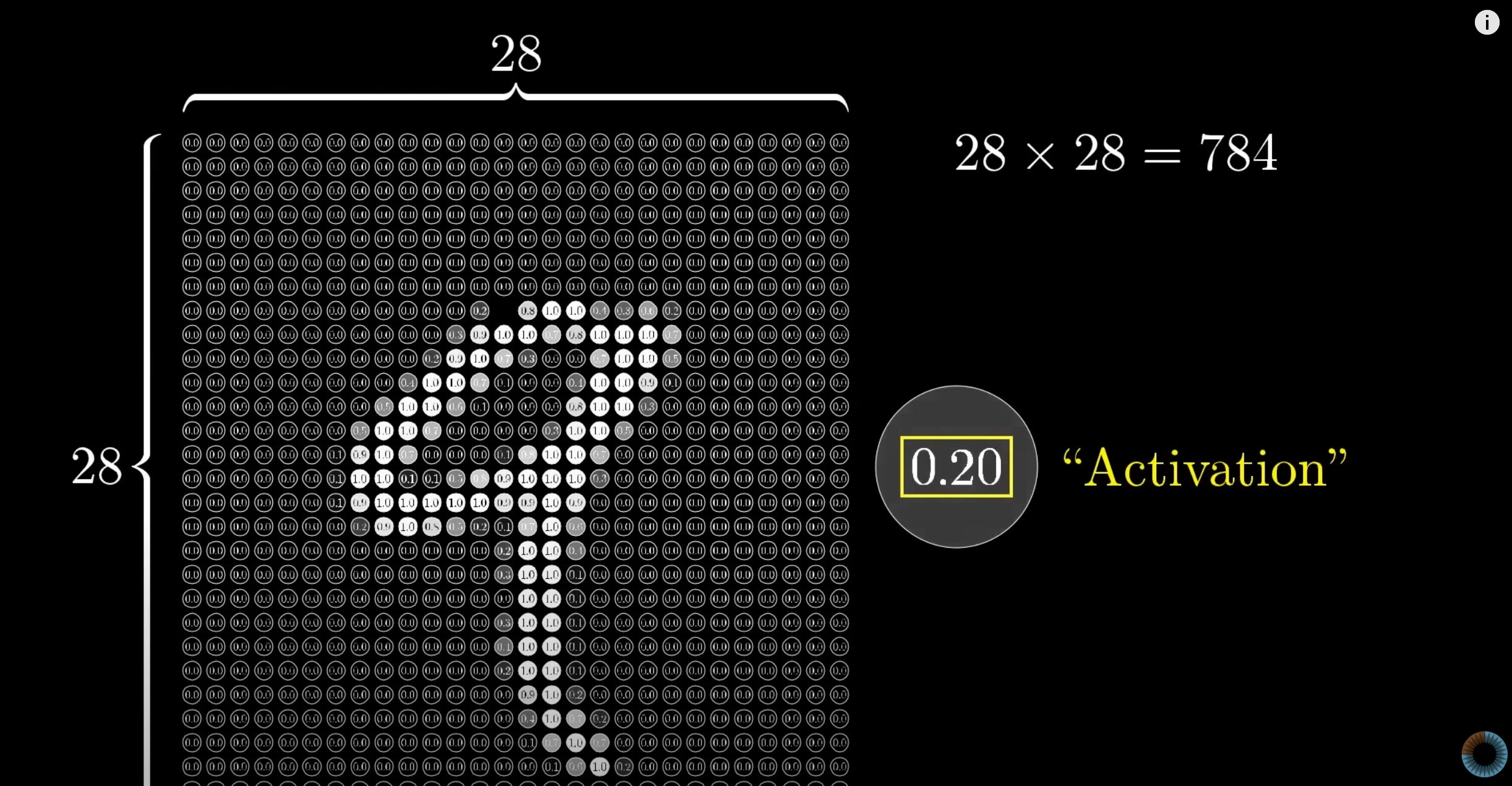
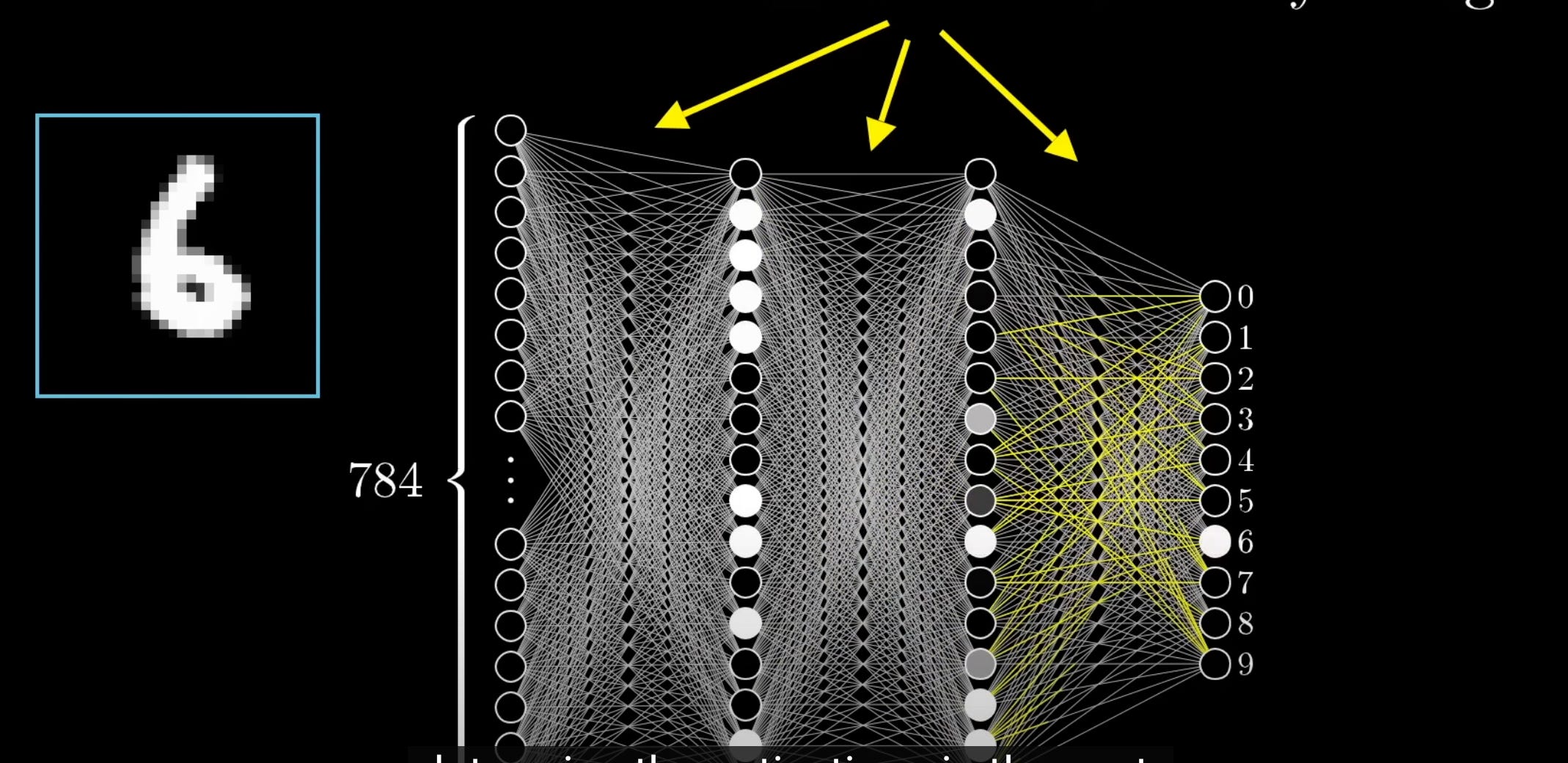
As you progress through the playlist, you can approximate a “model” as a black box that can take a 28x28 matrix and output a number, and note that inferencing is the process for doing this.
The next step is to break down the black box into a multi-variate formula, not dissimilar from algebraic formula for circle, sphere, etc - only, the “formula” here is a series of matrix multiplication with the variables being the weights, temperature, biases, etc.
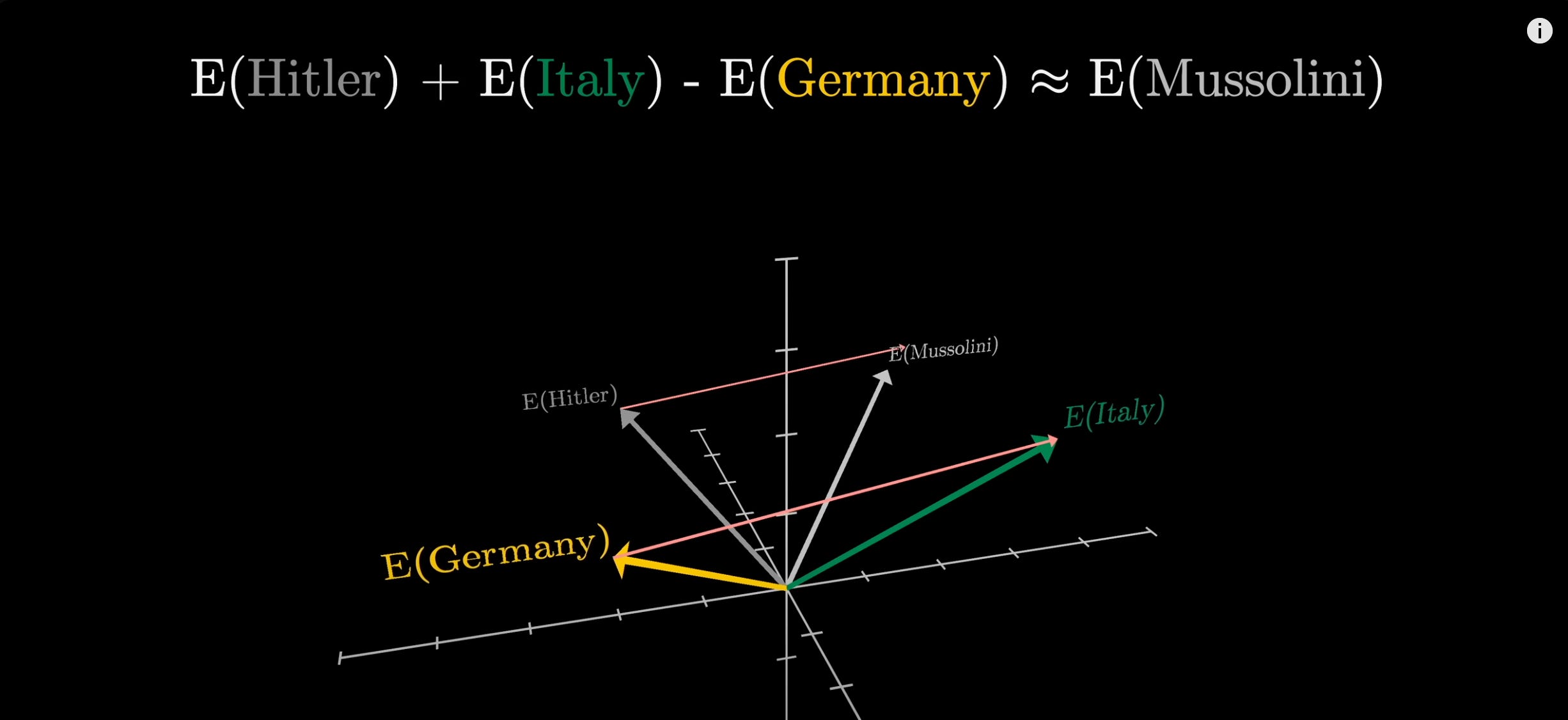
This video expanded that understanding to how LLMs work, and ways to represent concepts in a higher dimensional vector (embedding). As the screenshots indicate, the relationship between Germany and Italy is directionally similar to that between Hitler and Mussolini. Understanding this helped me hypothesise how the human meaning of concepts could be digitalised and how you could search for similar concepts by embedding them in a vector space.
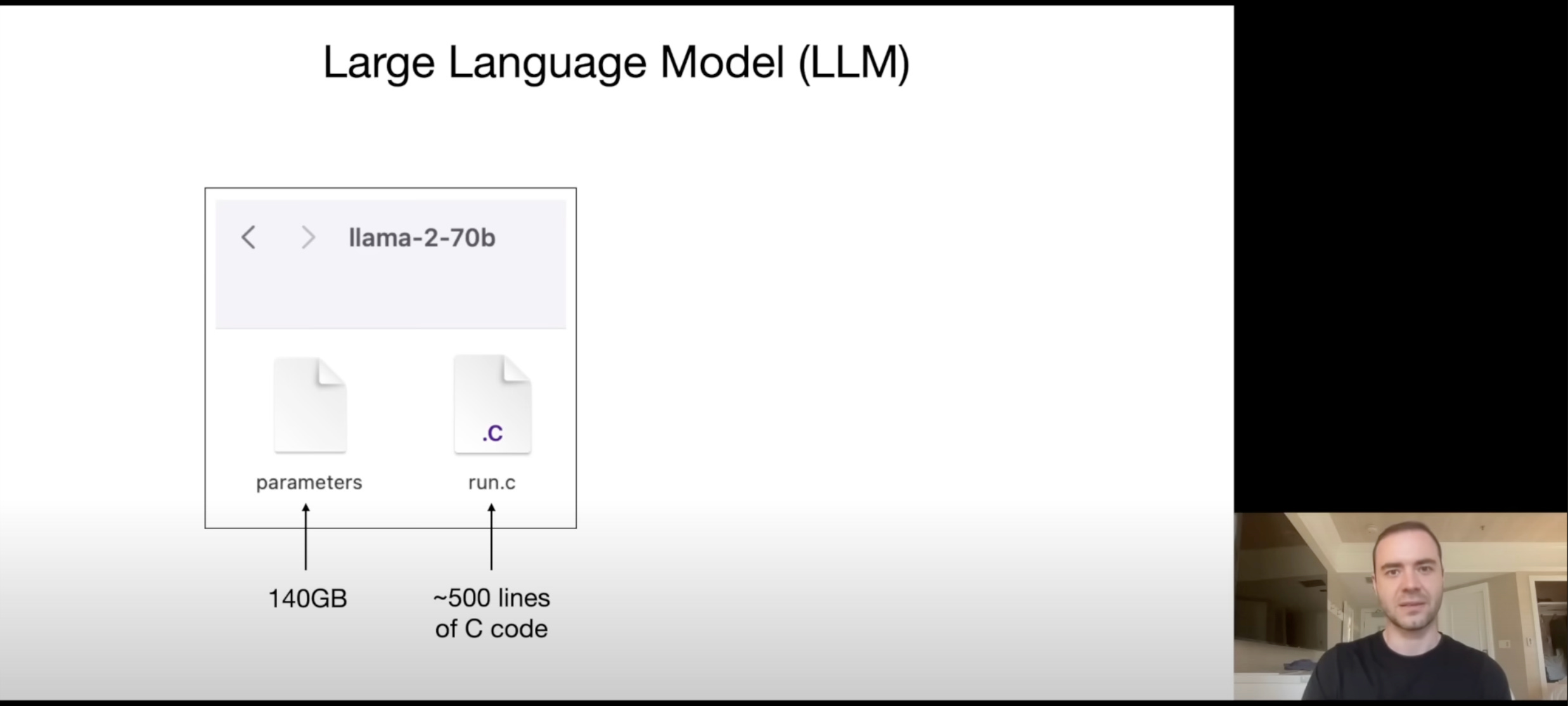
Lastly, just the first few minutes of this video from Andrej Karpathy broke down LLM inferencing into it simple matrix multiplication involving many floating point numbers. Llama-2-70b is essentially 70 Billion floating point numbers in a matrix format (each float = 2 bytes = 140 GB) and ~500 lines of code is how you process input through 70Billion numbers. Once I got my head around it, concepts like quantisation were just a baby step away.
Refining the model and testing it
The mental models are only as good as the information used to create the understanding. So, it’s important to learn from a diverse set of arguments from serious thinkers. With respect to the potential hype and risks of AI I’ve learnt a lot from Arvind Narayanan and Sayash Kapoor’s newsletter and X feeds, and can’t wait to read their books to learn more.
Creating Heuristics beyond the model
Once you have a working model and ways to improve it, it’s useful to abstract out a simple set of principles/framework to evaluate ideas when you don’t know enough specifics. The 4 principles from Ethan Mollick’s book Co-intellgence have been super useful in this regard. To paraphrase, my takeaways were:
Always invite AI to the table
Be the human in the loop
Treat AI like a person, but tell it what kind of person it is
Assume that the technology will keep improving
These have held well despite the rapid changes in this field and I am sure they will continue to do so for years to come. But I would also suggest trying to adapt the principles to align with your mental models in order to solidify your muscle memory.
Conclusion
I would love to learn from how others are approaching this objective. I intend to expand on my own framework for evaluating AI ideas soon. Meanwhile, please feel free to comment/DM with your thoughts/questions.